Textgain has launched

- News / Publishing
- Textgain API
Hi! We’ve just launched Textgain (https://textgain.com), an AI spin-off company from the University of Antwerp. We’re excited about our toolkit so far, and we’re brimming with ideas on how to improve it and where to go next. We hope you can be a part of it! Go ahead and take a look around. Ask us anything! Tell us how we can do better. We’ve bundled our tools on a single API page so you don’t have to skip around following links. There’s much more to come.
Big data. Let’s talk about big data first. Big data means a database that is so large or complex that it is difficult to process by hand. One example is the web. In other words, the massive wall of reviews, tweets, posts and emails about your (and other) products. And machine learning is the dynamite you need to break through.
Machine learning. In general, machine learning means that you show a machine examples of how something is done, so that it can learn to perform the task by itself – not unlike how humans learn to function in the world around them. Except that a machine is much faster and never gets bored or stubborn. There are many names for as many machine learning techniques: deep learning, neural networks, support vector machines, and so on, but it all comes down to training by example.
Text analytics. We’ve been using machine learning techniques on text for more than 10 years. We’ve trained machines that can understand text 1000x faster than we can, machines that detect trends, topics, threats, the age of the author, and much, much more. The web is buzzing with text. Our machines can read all of it, with no effort. We’ve bundled our know-how on text analytics into fast, robust, secure web services to help you gain customer insight by predicting text language, tone, topic, the age, gender, education and personality of the author, in English, in Dutch, or in a dozen other languages. You can get started for as little as $10 a month.
Sentiment. Some of our machines can guess whether the tone of a text is positive or negative (awesome book, awful movie, …) Consider that out of three people, one will disagree with the other two on anything about everything. This means that 70% accuracy is a pretty close representation of the opinion of any of your coworkers or friends, with the difference that a machine is faster and knows about more topics. Do you have a Twitter account? You can use our API to predict the sentiment about your products.
Here’s an idea of the accuracy for some of our services:
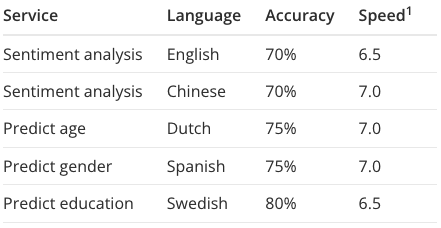
The accuracy is an average. We’ve trained our machines on a wide range of topics, from iPhone reviews and cat stories to stock news. Their knowledge may be sketchy on some topics (lowering the average) but other machines somewhere on the web may not know about these topic at all – you may be asking the opinion of a blessed fool or a narrow-minded specialist.
Here’s an idea of the language support for some of our services:
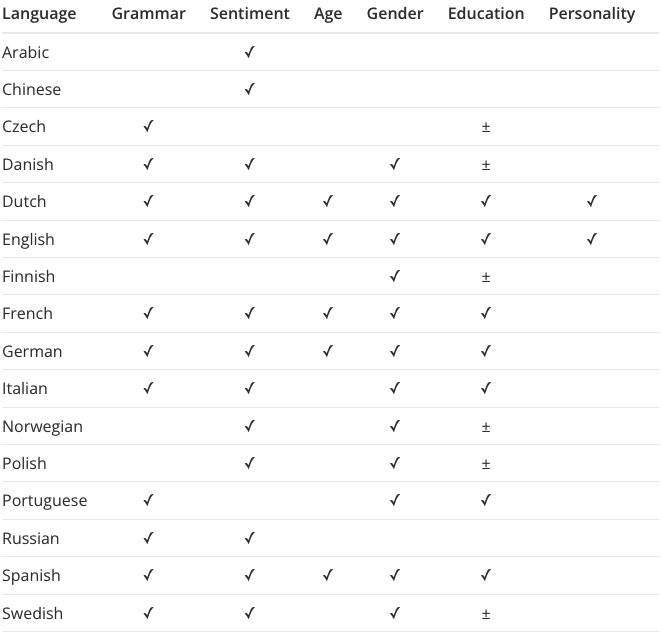
We also build tailored services. Tell us what you need. We can help with predictive analytics for security applications, such as identifying hate and depression.
If you have any text (tweets, reviews, …) that you want to analyze with a statistical predictive accuracy that rivals humans, contact us. We would love to talk to you about your business and about our products. We like smart machines but we love inspiring people even more.